
Merge nv main up to v2.10.0.dev0
Signed-off-by:  wenjh <wenjh@sugon.com>
wenjh <wenjh@sugon.com>
Showing
docs/examples/FP4_format.png
0 → 100644
{kind=link}
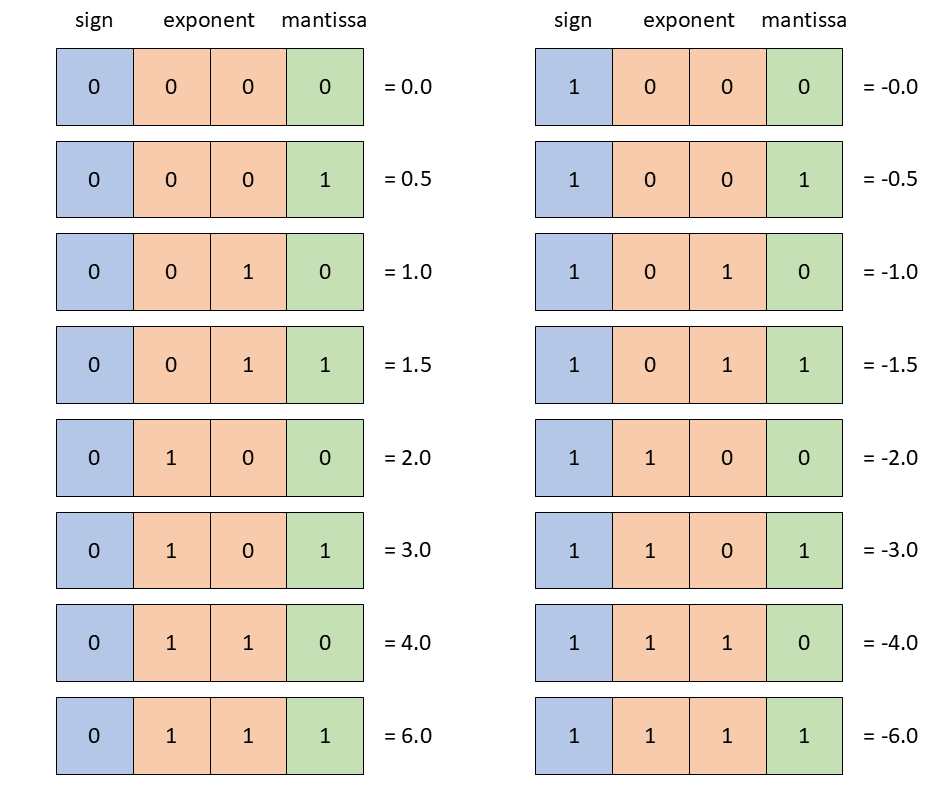
49.8 KB
docs/examples/FP4_linear.png
0 → 100644
{kind=link}
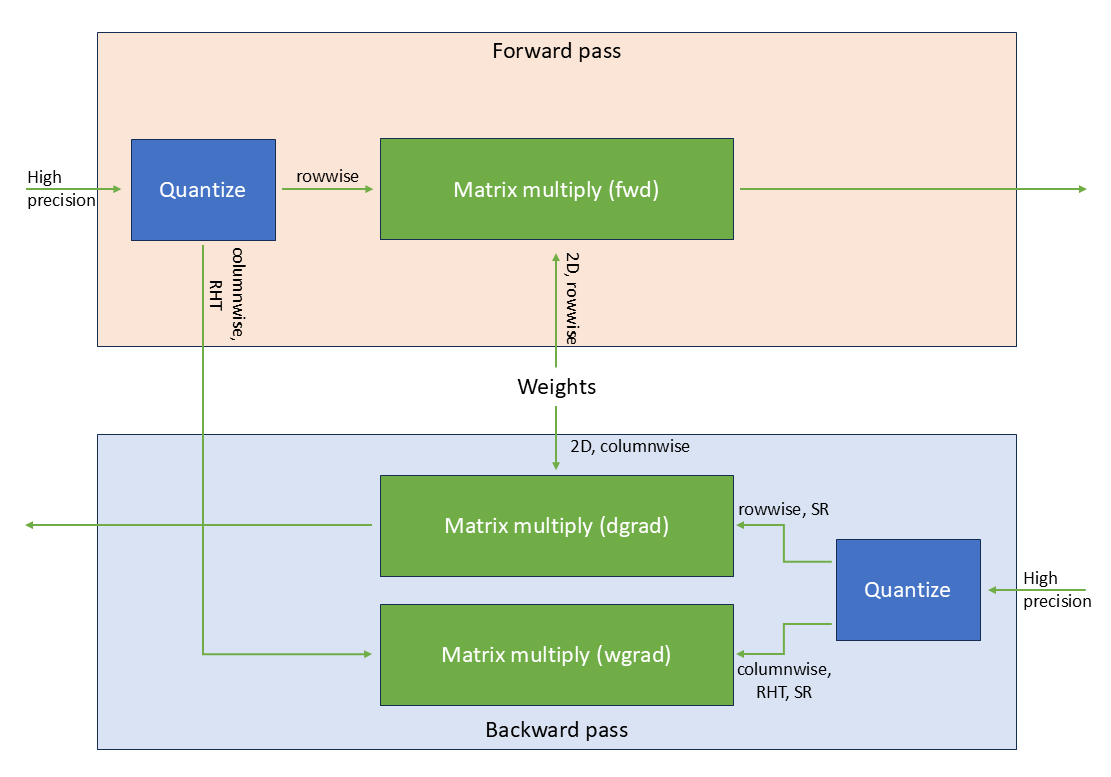
52.8 KB
Signed-off-by: wenjh <wenjh@sugon.com>
49.8 KB
52.8 KB