
Initial commit
parents
Showing
deep_ep/__init__.py
0 → 100644
deep_ep/buffer.py
0 → 100644
deep_ep/utils.py
0 → 100644
figures/low-latency.png
0 → 100644
{kind=link}
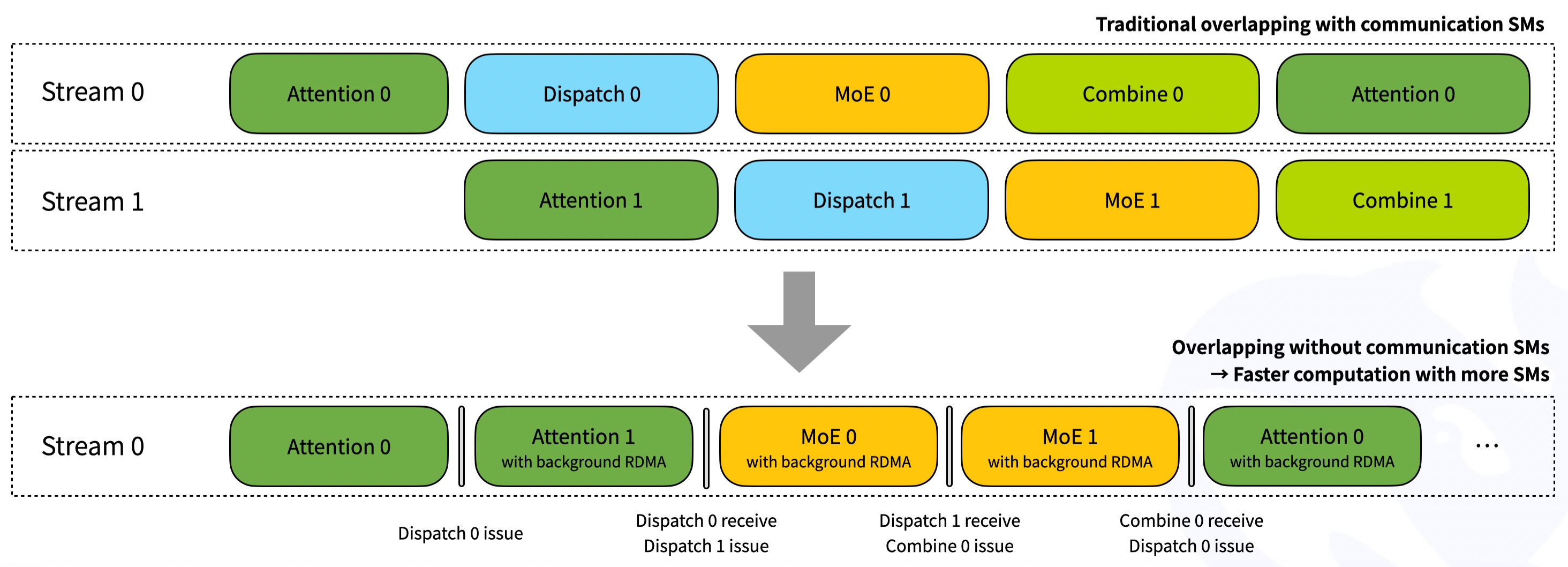
674 KB
figures/normal.png
0 → 100644
{kind=link}
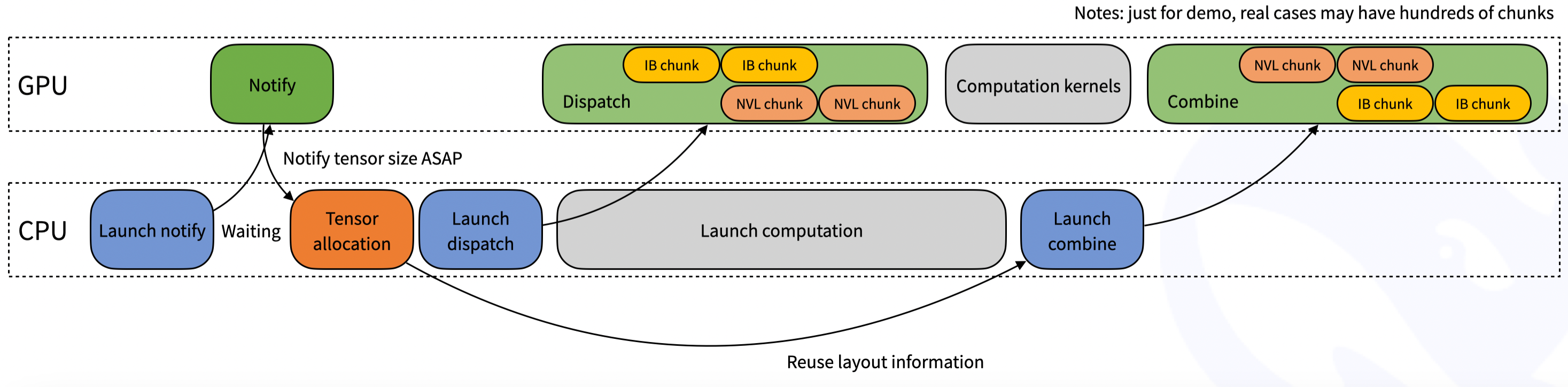
506 KB
setup.py
0 → 100644
tests/test_internode.py
0 → 100644
tests/test_intranode.py
0 → 100644
tests/test_low_latency.py
0 → 100644
tests/utils.py
0 → 100644
third-party/README.md
0 → 100644
third-party/nvshmem.patch
0 → 100644