[](https://arxiv.org/abs/2412.21037) [](https://huggingface.co/declare-lab/TangoFlux) [](https://tangoflux.github.io/) [](https://huggingface.co/spaces/declare-lab/TangoFlux) [](https://huggingface.co/datasets/declare-lab/CRPO) [](https://replicate.com/chenxwh/tangoflux)
* Powered by **Stability AI**
## Demos
[](https://huggingface.co/spaces/declare-lab/TangoFlux)
[](https://colab.research.google.com/github/declare-lab/TangoFlux/blob/main/Demo.ipynb)
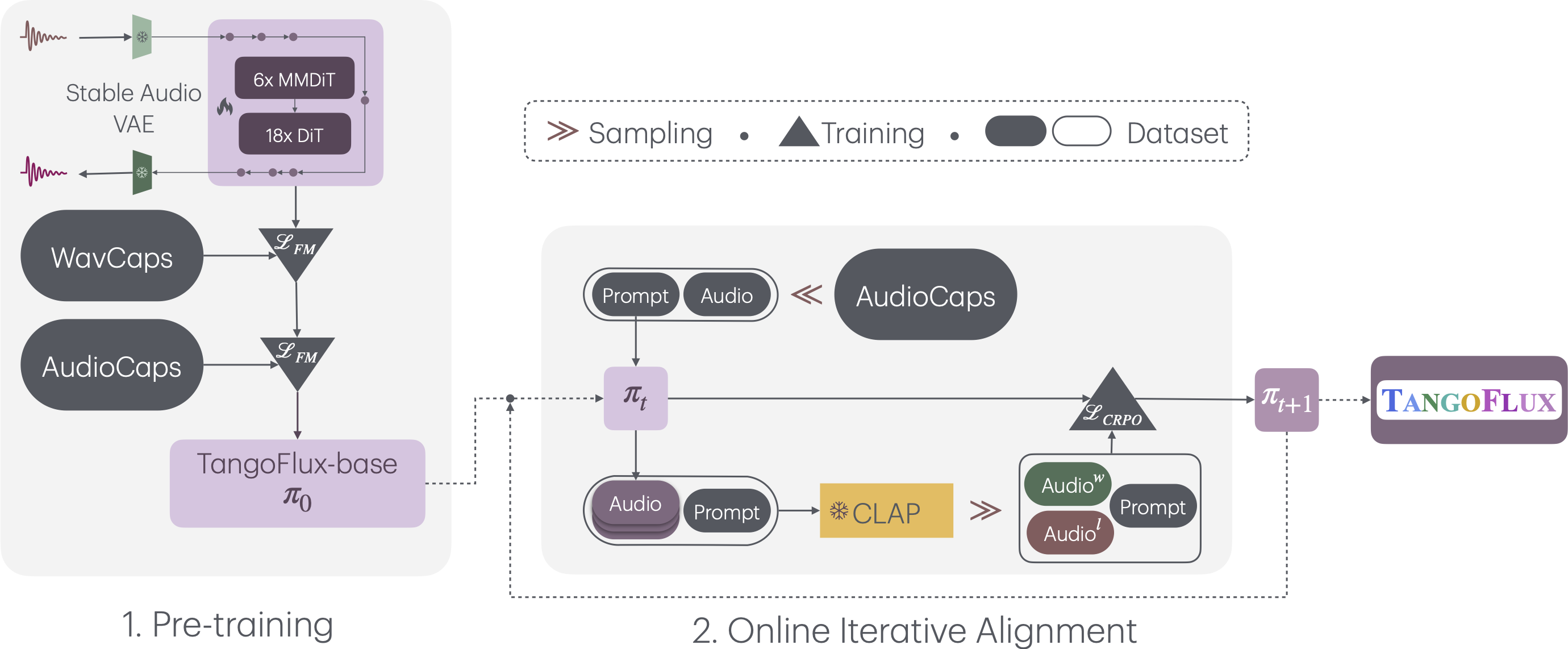
## Overall Pipeline
TangoFlux consists of FluxTransformer blocks, which are Diffusion Transformers (DiT) and Multimodal Diffusion Transformers (MMDiT) conditioned on a textual prompt and a duration embedding to generate a 44.1kHz audio up to 30 seconds long. TangoFlux learns a rectified flow trajectory to an audio latent representation encoded by a variational autoencoder (VAE). TangoFlux training pipeline consists of three stages: pre-training, fine-tuning, and preference optimization with CRPO. CRPO, particularly, iteratively generates new synthetic data and constructs preference pairs for preference optimization using DPO loss for flow matching.
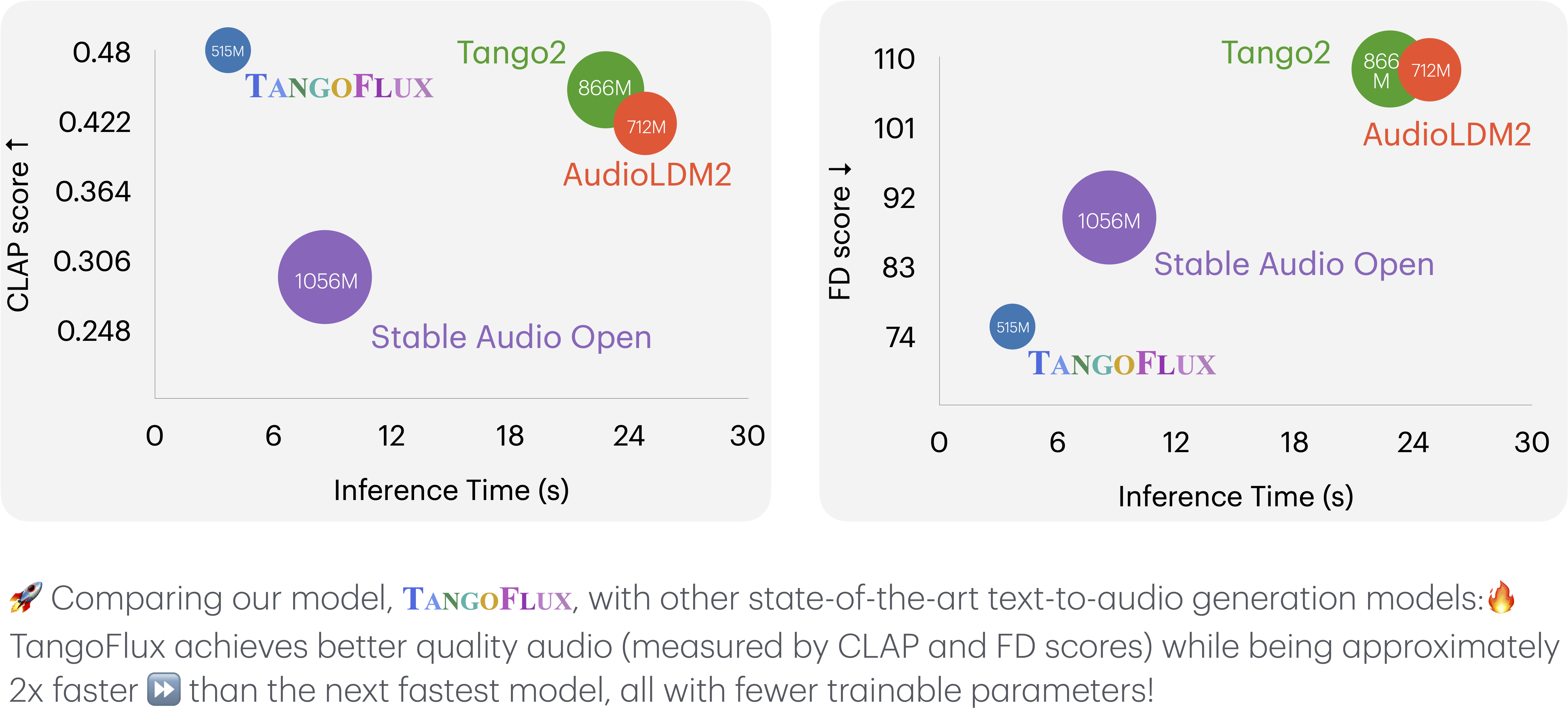
🚀 **TangoFlux can generate 44.1kHz stereo audio up to 30 seconds in ~3 seconds on a single A40 GPU.**
## Installation
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.3.0-ubuntu22.04-dtk24.04.3-py3.10
git clone 代码文件
```bash
pip install -e .
```
## Inference
TangoFlux can generate audio up to 30 seconds long. You must pass a duration to the `model.generate` function when using the Python API. Please note that duration should be between 1 and 30.
### Web Interface
Run the following command to start the web interface:
```bash
tangoflux-demo
```
### CLI
Use the CLI to generate audio from text.
```bash
tangoflux "Hammer slowly hitting the wooden table" output.wav --duration 10 --steps 50
```
### Python API
```python
import torchaudio
from tangoflux import TangoFluxInference
model = TangoFluxInference(name='declare-lab/TangoFlux')
audio = model.generate('Hammer slowly hitting the wooden table', steps=50, duration=10)
torchaudio.save('output.wav', audio, 44100)
```
### [ComfyUI](https://github.com/comfyanonymous/ComfyUI)
> This ui will let you design and execute advanced stable diffusion pipelines using a graph/nodes/flowchart based interface.
Check [this](https://github.com/LucipherDev/ComfyUI-TangoFlux) repo for the TangoFlux custom node for *ComfyUI*. (Thanks to [LucipherDev](https://github.com/LucipherDev))
Our evaluation shows that inference with 50 steps yields the best results. A CFG scale of 3.5, 4, and 4.5 yield similar quality output. Inference with 25 steps yields similar audio quality at a faster speed.
## Training
We use the `accelerate` package from Hugging Face for multi-GPU training. Run `accelerate config` to setup your run configuration. The default accelerate config is in the `configs` folder. Please specify the path to your training files in the `configs/tangoflux_config.yaml`. Samples of `train.json` and `val.json` have been provided. Replace them with your own audio.
`tangoflux_config.yaml` defines the training file paths and model hyperparameters:
```bash
HIP_VISIBLE_DEVICES=0,1 accelerate launch --config_file='configs/accelerator_config.yaml' tangoflux/train.py --checkpointing_steps="best" --save_every=5 --config='configs/tangoflux_config.yaml'
```
To perform DPO training, modify the training files such that each data point contains "chosen", "reject", "caption" and "duration" fields. Please specify the path to your training files in `configs/tangoflux_config.yaml`. An example has been provided in `train_dpo.json`. Replace it with your own audio.
```bash
HIP_VISIBLE_DEVICES=0,1 accelerate launch --config_file='configs/accelerator_config.yaml' tangoflux/train_dpo.py --checkpointing_steps="best" --save_every=5 --config='configs/tangoflux_config.yaml'
```
## Evaluation Scripts
## TangoFlux vs. Other Audio Generation Models
This key comparison metrics include:
- **Output Length**: Represents the duration of the generated audio.
- **FD**