[](https://arxiv.org/abs/2412.21037) [](https://huggingface.co/declare-lab/TangoFlux) [](https://tangoflux.github.io/) [](https://huggingface.co/spaces/declare-lab/TangoFlux) [](https://huggingface.co/datasets/declare-lab/CRPO)
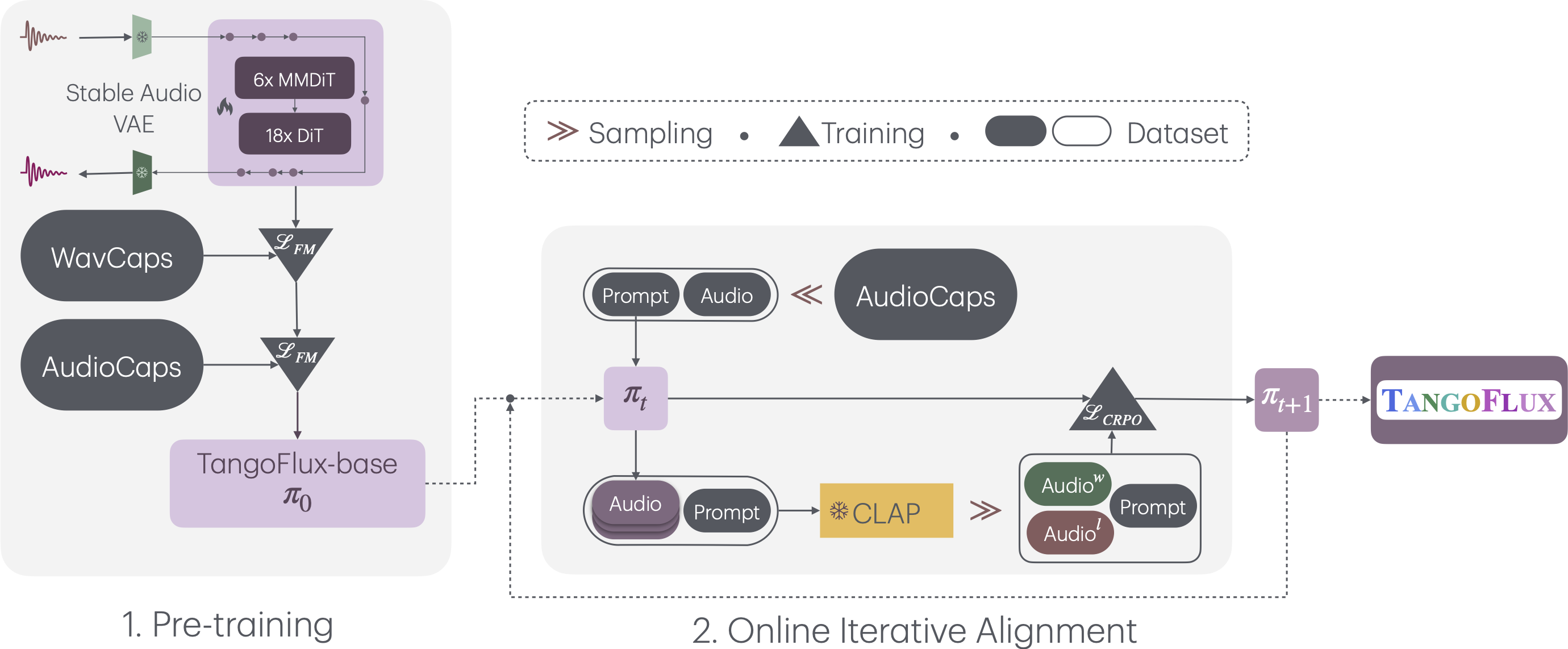
## Overall Pipeline
TangoFlux consists of FluxTransformer blocks which are Diffusion Transformer (DiT) and Multimodal Diffusion Transformer (MMDiT), conditioned on textual prompt and duration embedding to generate audio at 44.1kHz up to 30 seconds. TangoFlux learns a rectified flow trajectory from audio latent representation encoded by a variational autoencoder (VAE). The TangoFlux training pipeline consists of three stages: pre-training, fine-tuning, and preference optimization. TangoFlux is aligned via CRPO which iteratively generates new synthetic data and constructs preference pairs to perform preference optimization.
## Quickstart
TangoFlux is a Text To Audio (TTA) Model that is capable of generating stereo audio up to 30 seconds at 44.1kHz in about 3 seconds.
## Training TangoFlux
We use the accelerate package from Hugging Face for multi-gpu training. Run accelerate config from terminal and set up your run configuration by the answering the questions asked. We have default an accelerator config in the configs folder.
The tangoflux_config defines the training and model hyperparamter
```
CUDA_VISISBLE_DEVICES=0,1 accelerate launch --config_file='configs/accelerator_config.yaml' src/train.py --checkpointing_steps="best" --save_every=5 --config='configs/tangoflux_config.yaml'
```
## Inference with TangoFlux
Download the TangoFlux model and generate audio from a text prompt:
TangoFlux can generate audio up to 30seconds through passing in a duration variable in model.generate function.
```python
import torchaudio
from tangoflux import TangoFluxInference
from IPython.display import Audio
model = TangoFluxInference(name='declare-lab/TangoFlux')
audio = model.generate('Hammer slowly hitting the wooden table', steps=50, duration=10)
Audio(data=audio, rate=44100)
```
Our evaluation shows that inferencing with 50 steps yield the best results. A CFG scale of 3.5,4,4.5 yields simliar quality.
For faster inference, consider setting steps to 25 that yield similar audio quality.
## Evaluation Scripts
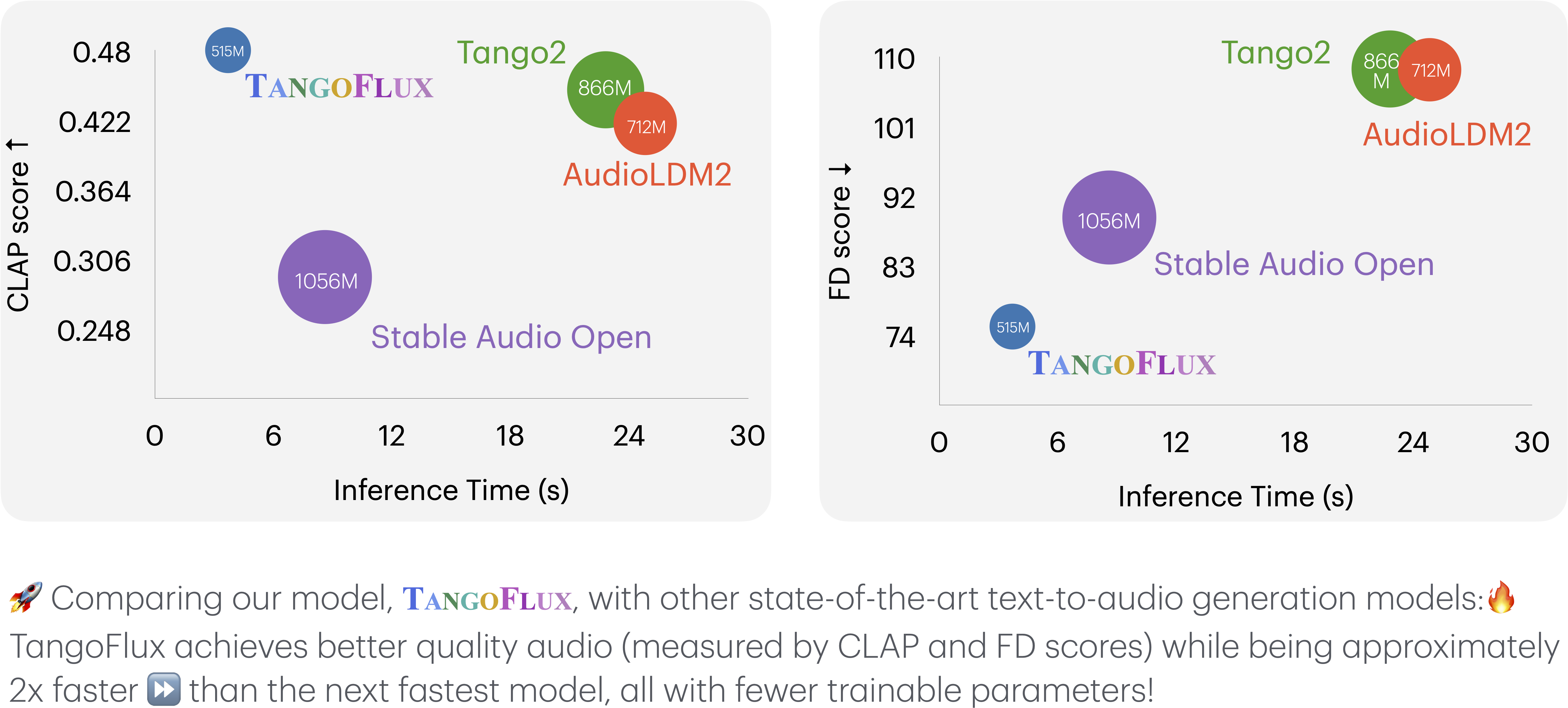
## Comparison Between TangoFlux and Other Audio Generation Models
This comparison evaluates TangoFlux and other audio generation models across various metrics. Key metrics include:
- **Output Length**: Represents the duration of the generated audio.
- **FD**