
Initial release
parents
Showing
app/t2i/data/__init__.py
0 → 100644
app/t2i/evaluate.py
0 → 100644
app/t2i/generate.py
0 → 100644
app/t2i/get_metrics.py
0 → 100644
app/t2i/latency.py
0 → 100644
app/t2i/metrics/__init__.py
0 → 100644
app/t2i/metrics/fid.py
0 → 100644
app/t2i/run_gradio.py
0 → 100644
app/t2i/utils.py
0 → 100644
app/t2i/vars.py
0 → 100644
assets/efficiency.jpg
0 → 100644
{kind=link}
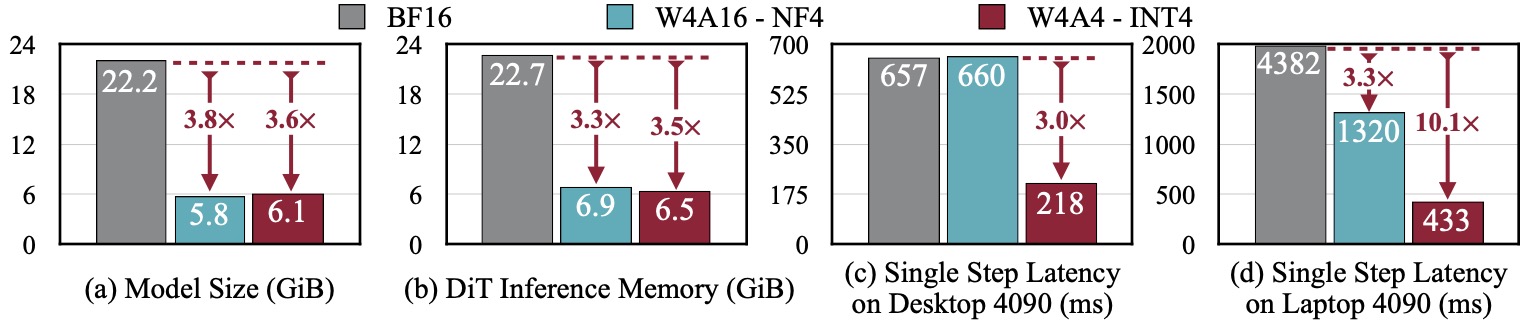
113 KB
assets/engine.jpg
0 → 100644
{kind=link}
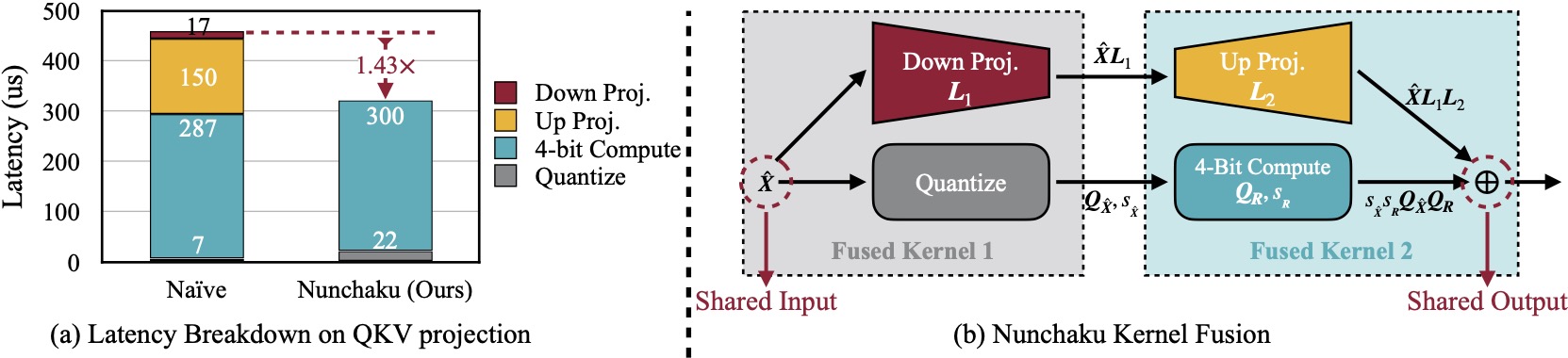
128 KB
assets/intuition.gif
0 → 100644
{kind=link}

287 KB
assets/logo.png
0 → 100644
{kind=link}
25.8 KB
assets/logo.svg
0 → 100644
{kind=link}
assets/lora.jpg
0 → 100644
{kind=link}

1010 KB
assets/speed_demo.gif
0 → 100644
{kind=link}
1.02 MB