
Merge branch 'main' of github.com:mit-han-lab/nunchaku into dev
Showing
README_ZH.md
0 → 100644
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}
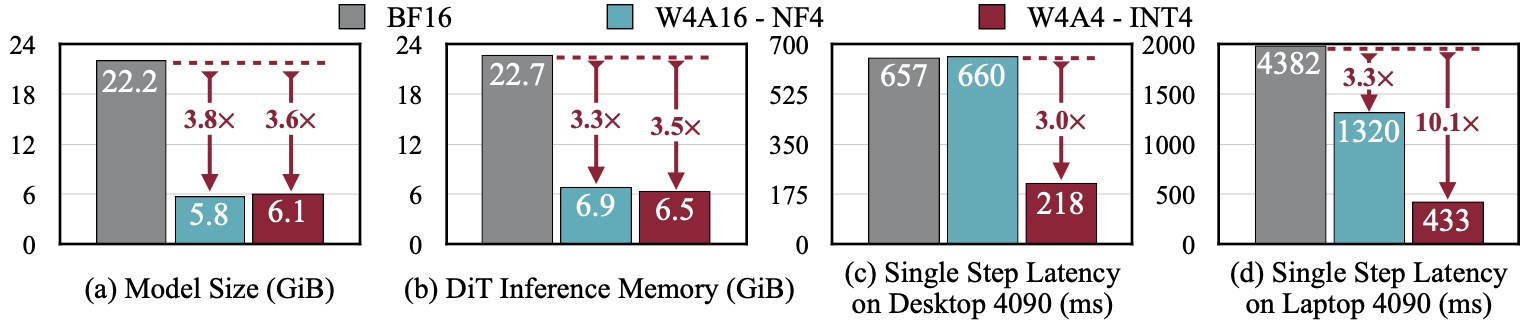
| W: | H:

| W: | H:
{kind=link}
{kind=link}

| W: | H:

| W: | H:
docs/setup_windows.md
0 → 100644