# StableTTS
StableTTS是一款用于中英文语音生成的快速轻量级TTS模型,只有10M参数。
## 论文
`未发表论文`
## 模型结构
受Stable Diffusion 3的启发,将流匹配和DiT相结合成开源TTS模型。
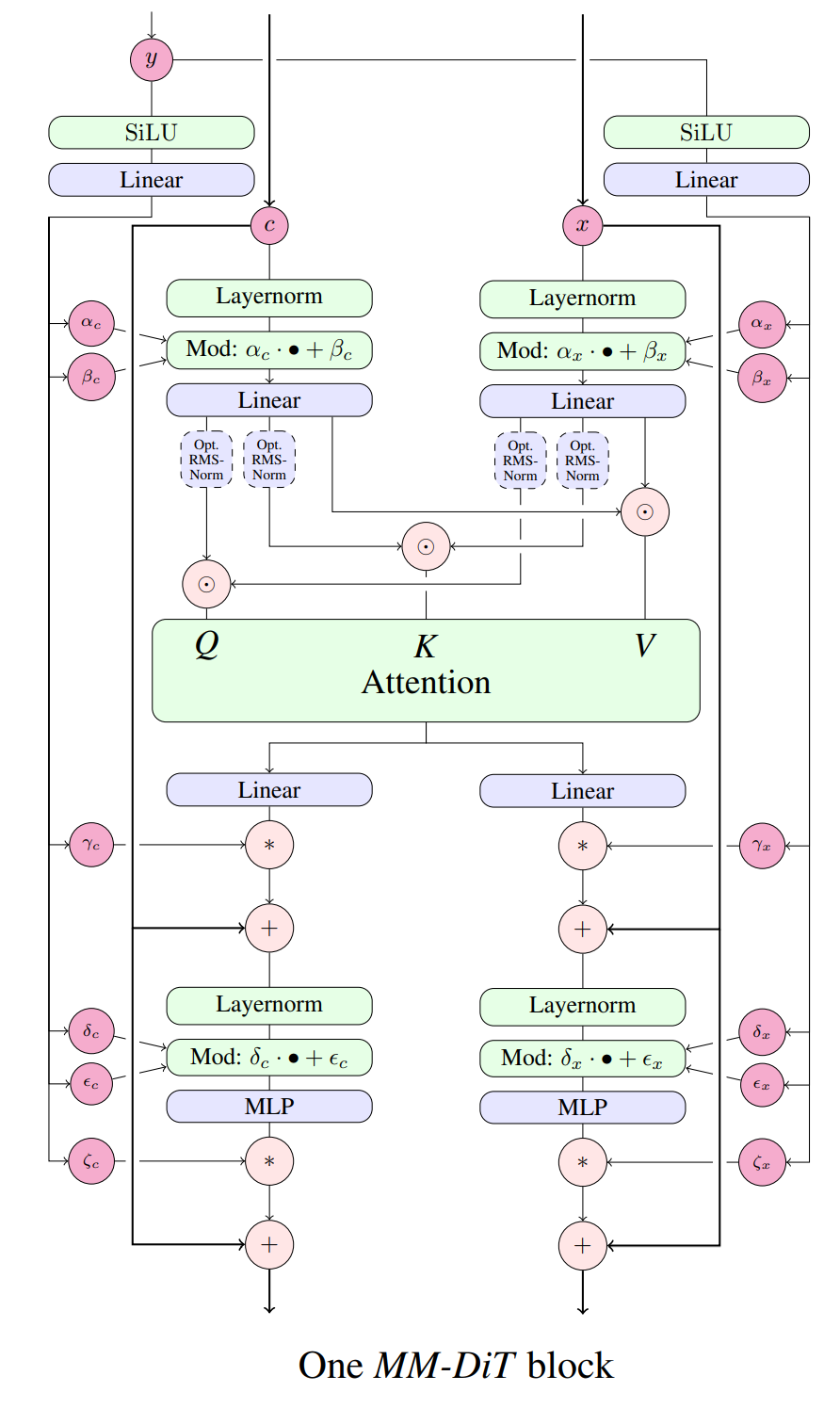
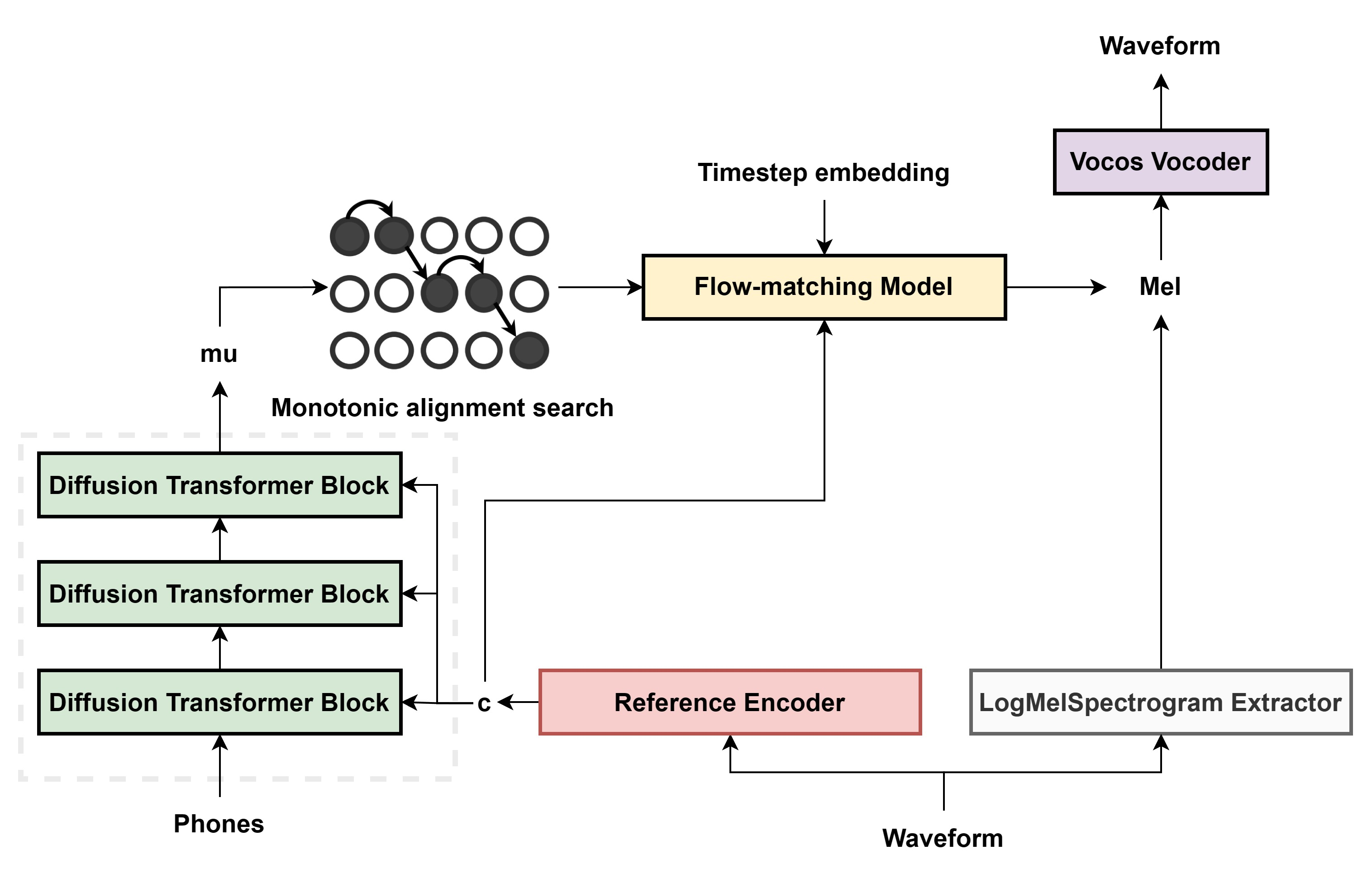
## 算法原理
Hierspeech++的扩散卷积转换器模块是原始 DiT和FFT的组合,以获得更好的韵律,流匹配解码器中,在DiT模块之前添加一个FiLM层,以条件时间步长嵌入到模型中。
## 环境配置
```
mv stabletts_pytorch StableTTS # 去框架名后缀
```
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-centos7.6-dtk23.10-py38
# 为以上拉取的docker的镜像ID替换,本镜像为:ffa1f63239fc
docker run -it --shm-size=32G -v $PWD/StableTTS:/home/StableTTS -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name stabletts bash
cd /home/StableTTS
pip install -r requirements.txt # requirements.txt
# torchaudio可从whl.zip文件里获取安装:
pip install torchaudio-2.1.2+4b32183.abi0.dtk2310.torch2.1.0a0-cp38-cp38-linux_x86_64.whl
```
### Dockerfile(方法二)
```
cd StableTTS/docker
docker build --no-cache -t stabletts:latest .
docker run --shm-size=32G --name stabletts -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video -v $PWD/../../StableTTS:/home/StableTTS -it stabletts bash
# 若遇到Dockerfile启动的方式安装环境需要长时间等待,可注释掉里面的pip安装,启动容器后再安装python库:pip install -r requirements.txt。
# torchaudio可从whl.zip文件里获取安装:
pip install torchaudio-2.1.2+4b32183.abi0.dtk2310.torch2.1.0a0-cp38-cp38-linux_x86_64.whl
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装:
- https://developer.hpccube.com/tool/
```
DTK驱动:dtk23.10
python:python3.8
torch:2.1.0
torchvision:0.16.0
torchaudio:2.1.2
```
```
# torchaudio可从whl.zip文件里获取安装:
pip install torchaudio-2.1.2+4b32183.abi0.dtk2310.torch2.1.0a0-cp38-cp38-linux_x86_64.whl
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应。`
2、其它非特殊库参照requirements.txt安装
```
pip install -r requirements.txt # requirements.txt
```
## 数据集
本步骤说明采用标贝女声数据集`BZNSYP`,其余音色数据参照[`recipes`](./recipes/)下的文件说明进行下载使用,项目中已提供[`BZNSYP`](./recipes/raw_datasets/BZNSYP.zip)迷你数据集进行试用,解压即可,完整BZNSYP数据集请从以下官网或通过SCNet高速通道下载:
- https://www.data-baker.com/data/index/TNtts/
- http://113.200.138.88:18080/aidatasets/project-dependency/bznsyp/-/tree/master
数据目录结构如下:
```
recipes/raw_datasets/BZNSYP
├── Wave
├── ├── xxx.wav
├── └── xxx.wav
└── PhoneLabeling
├── ├── xxx.interval
├── └── xxx.interval
└── ProsodyLabeling
├── └── 000001-010000.txt
```
数据预处理命令为:
```
cd recipes
python BZNSYP_标贝女声.py
mv filelists/bznsyp.txt ../filelists/filelist.txt
cd ..
python preprocess.py # 生成训练需要用的filelists/filelist.json与stableTTS_datasets/mels
```
## 训练
### 单机单卡
```
export HIP_VISIBLE_DEVICES=0
cd StableTTS
python train.py
```
更多资料可参考源项目的[`README_origin`](./README_origin.md)
## 推理
100h chinese: `checkpoint-zh_0.pt`
- [huggingface](https://huggingface.co/KdaiP/StableTTS/blob/main/checkpoint-zh_0.pt)
- [SCNet](http://113.200.138.88:18080/aimodels/findsource-dependency/stabletts_pytorch/-/blob/master/checkpoint-zh_0.pt)
2k english + chinese + japanese: `vocoder.pt`
- [huggingface](https://huggingface.co/KdaiP/StableTTS/blob/main/vocoder.pt)
- [SCNet](http://113.200.138.88:18080/aimodels/findsource-dependency/stabletts_pytorch/-/blob/master/vocoder.pt)
```
export HIP_VISIBLE_DEVICES=0
mv vocoder.pt ./checkpoints/vocoder.pt
python inference.py
# 使用默认权重:
# tts_checkpoint_path = './checkpoints/checkpoint-zh_0.pt'
# vocoder_checkpoint_path = './checkpoints/vocoder.pt'。
```
## result
`输入:`
```
'你好,世界!' # 文本
'./audio.wav' # 音色
```
`输出:`
```
'generate.wav' # 合成声音
```
### 精度
max epoch为1000,推理框架:pytorch。
| device | Loss |
|:---------:|:------:|
| DCU Z100L | 1.9369 |
| GPU V100S | 1.9382 |
## 应用场景
### 算法类别
`语音合成`
### 热点应用行业
`金融,电商,教育,制造,医疗,能源`
## 源码仓库及问题反馈
- http://developer.hpccube.com/codes/modelzoo/stabletts_pytorch.git
## 参考资料
- https://github.com/KdaiP/StableTTS.git
- https://stabilityai-public-packages.s3.us-west-2.amazonaws.com/Stable+Diffusion+3+Paper.pdf