# StableTTS
Next-generation TTS model using flow-matching and DiT, inspired by [Stable Diffusion 3](https://stability.ai/news/stable-diffusion-3).
## Introduction
As the first open-source TTS model that tried to combine flow-matching and DiT, StableTTS is a fast and lightweight TTS model for chinese and english speech generation. It has only 10M parameters.
✨ **Huggingface demo:** [chinese_version](https://huggingface.co/spaces/KdaiP/StableTTS_zh-demo) [english_version](https://huggingface.co/spaces/KdaiP/StableTTS_en-demo)
## Pretrained models
We provide pretrained models ready for inference, finetuning and webui. Simply download and place the models in the `./checkpoints` directory to get started.
| Model Name | Task Details | Dataset | Download Link |
|:----------:|:------------:|:-------------:|:-------------:|
| StableTTS | text to mel | 400h english | [🤗](https://huggingface.co/KdaiP/StableTTS/blob/main/checkpoint-en_0.pt)|
| StableTTS | text to mel | 100h chinese | [🤗](https://huggingface.co/KdaiP/StableTTS/blob/main/checkpoint-zh_0.pt)|
| Vocos | mel to wav | 2k english + chinese + japanese | [🤗](https://huggingface.co/KdaiP/StableTTS/blob/main/vocoder.pt)|
**Larger models, better pretrained models and multilingual models will comming soon...**
## Installation
1. **Set up pytorch**: Follow the [official PyTorch guide](https://pytorch.org/get-started/locally/) to install pytorch and torchaudio. We recommend using the latest version for optimal performance.
2. **Install Dependencies**: Run the following command to install the required Python packages:
```bash
pip install -r requirements.txt
```
## Inference
For detailed inference instructions, please refer to `inference.ipynb`
We also provide a webui based on gradio, please refer to `webui.py`
## Training
Training your models with StableTTS is designed to be straightforward and efficient. Here’s how to get started:
### Preparing Your Data
1. **Generate Text and Audio pairs**: Generate the text and audio pair filelist as `./filelists/example.txt`. Some recipes of open-source datasets could be found in `./recipes`.
2. **Run Preprocessing**: Adjust the `DataConfig` in `preprocess.py` to set your input and output paths, then run the script. This will process the audio and text according to your list, outputting a JSON file with paths to mel features and phonemes. **Note: Ensure to change `language = 'chinese'` in `DataConfig` for English or Japanese text processing.**
Note: Since we use `reference encoder` to capture speaker identity when training, there is no need for a speaker ID in multispeaker synthesis and training.
### Start training
1. **Adjust Training Configuration**: In `config.py`, modify `TrainConfig` to set your file list path and adjust training parameters as needed.
2. **Start the Training Process**: Launch `train.py` to start training your model.
Note: For finetuning, download the pretrained model and place it in the `model_save_path` directory specified in `TrainConfig`. Training script will automatically detect and load the pretrained checkpoint.
### Experiment with Configurations
Feel free to explore and modify settings in `config.py` to modify the hyperparameters!
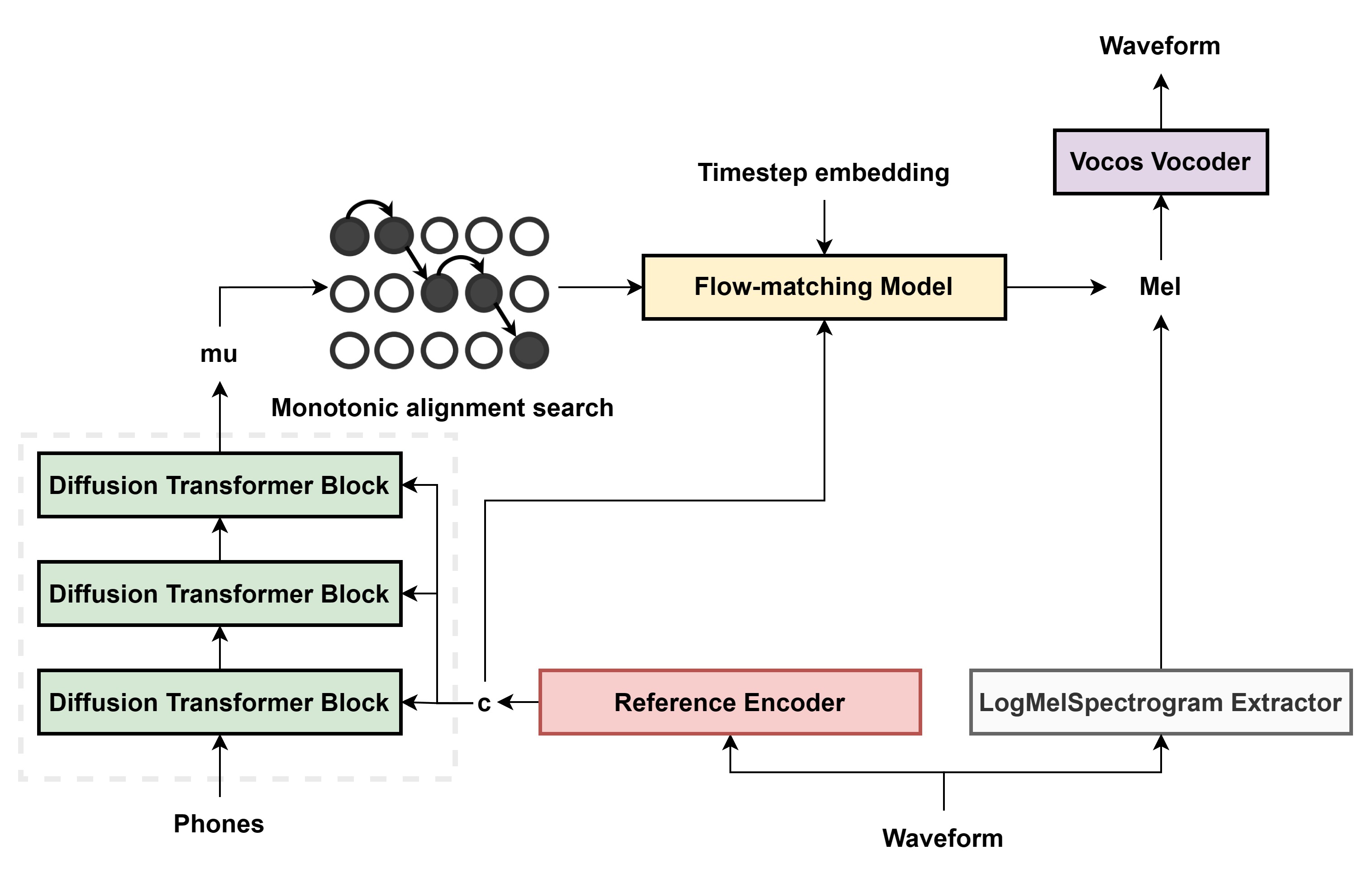
## Model structure
- We use the Diffusion Convolution Transformer block from [Hierspeech++](https://github.com/sh-lee-prml/HierSpeechpp), which is a combination of original [DiT](https://github.com/sh-lee-prml/HierSpeechpp) and [FFT](https://arxiv.org/pdf/1905.09263.pdf)(Feed forward Transformer from fastspeech) for better prosody.
- In flow-matching decoder, we add a [FiLM layer](https://arxiv.org/abs/1709.07871) before DiT block to condition timestep embedding into model. We also add three ConvNeXt blocks before DiT. We found it helps with model convergence and better sound quality
## References
The development of our models heavily relies on insights and code from various projects. We express our heartfelt thanks to the creators of the following:
### Direct Inspirations
[Matcha TTS](https://github.com/shivammehta25/Matcha-TTS): Essential flow-matching code.
[Grad TTS](https://github.com/huawei-noah/Speech-Backbones/tree/main/Grad-TTS): Diffusion model structure.
[Stable Diffusion 3](https://stability.ai/news/stable-diffusion-3): Idea of combining flow-matching and DiT.
[Vits](https://github.com/jaywalnut310/vits): Code style and MAS insights, DistributedBucketSampler.
### Additional References:
[plowtts-pytorch](https://github.com/p0p4k/pflowtts_pytorch): codes of MAS in training
[Bert-VITS2](https://github.com/Plachtaa/VITS-fast-fine-tuning) : numba version of MAS and modern pytorch codes of Vits
[fish-speech](https://github.com/fishaudio/fish-speech): dataclass usage and mel-spectrogram transforms using torchaudio
[gpt-sovits](https://github.com/RVC-Boss/GPT-SoVITS): melstyle encoder for voice clone
[diffsinger](https://github.com/openvpi/DiffSinger): chinese three section phoneme scheme for chinese g2p
[coqui xtts](https://huggingface.co/spaces/coqui/xtts): gradio webui
## TODO
- [ ] Release pretrained models.
- [ ] Provide detailed finetuning instructions.
- [x] Support Japanese language.
- [ ] User friendly preprocess and inference script.
- [ ] Enhance documentation and citations.
- [ ] Add chinese version of readme.
- [ ] Release multilingual checkpoint.
## Disclaimer
Any organization or individual is prohibited from using any technology in this repo to generate or edit someone's speech without his/her consent, including but not limited to government leaders, political figures, and celebrities. If you do not comply with this item, you could be in violation of copyright laws.