
v1.0
parents
Showing
docker_start.sh
0 → 100644
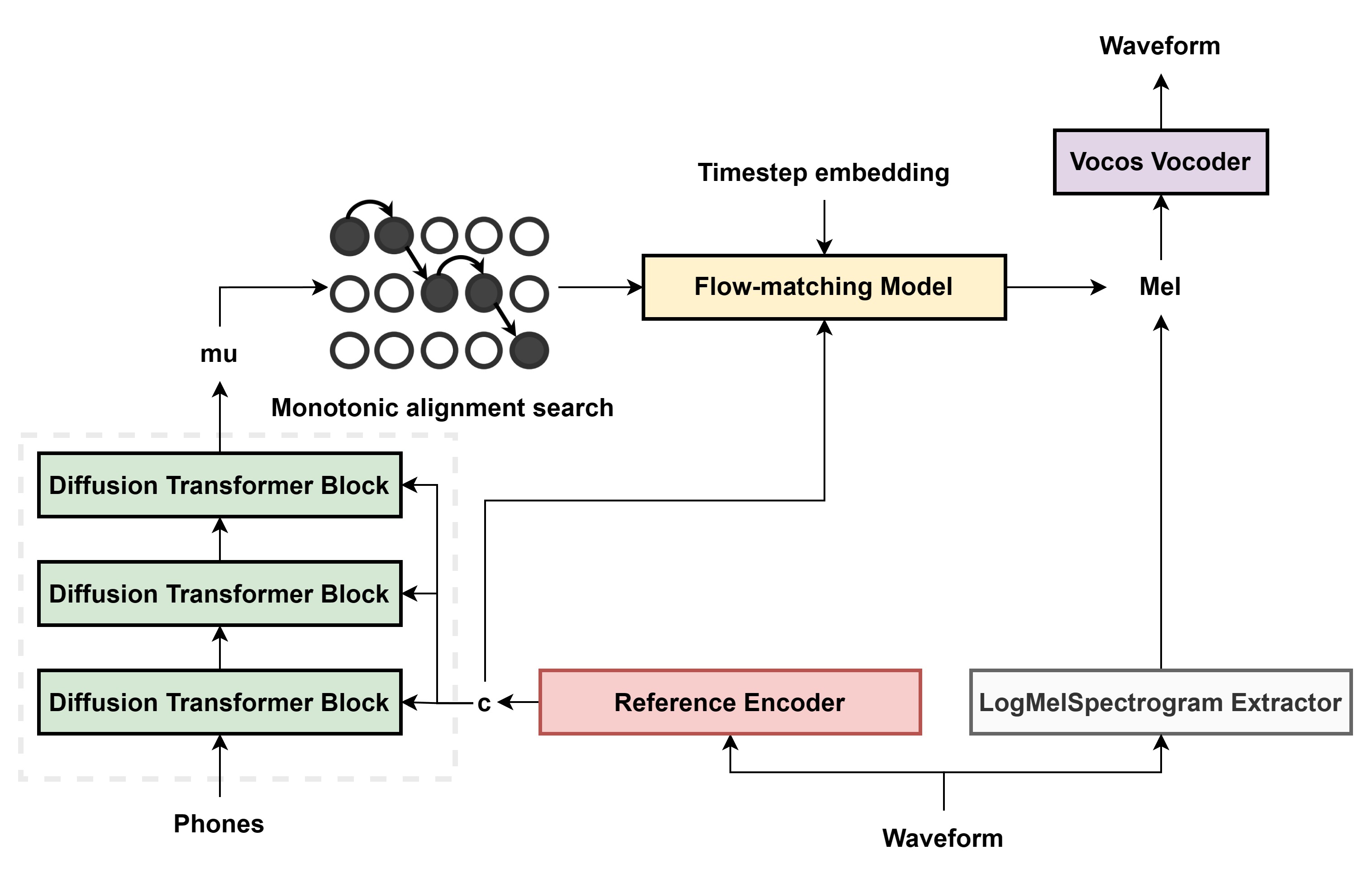
figures/structure.jpg
0 → 100644
{kind=link}
284 KB
filelists/example.txt
0 → 100644
generate.wav
0 → 100644
File added
inference.ipynb
0 → 100644
inference.py
0 → 100644
model.properties
0 → 100644
models/__init__.py
0 → 100644
models/dit.py
0 → 100644
models/duration_predictor.py
0 → 100644
models/estimator.py
0 → 100644
models/flow_matching.py
0 → 100644
models/model.py
0 → 100644
models/reference_encoder.py
0 → 100644
models/text_encoder.py
0 → 100644
monotonic_align/__init__.py
0 → 100644
monotonic_align/core.py
0 → 100644
preprocess.py
0 → 100644
recipes/AiSHELL3.py
0 → 100644
recipes/BZNSYP_标贝女声.py
0 → 100644